where ei are independent random variables with E(ei)=0 and Var(ei)=σ2.
The xi are assumed to be fixed. This is referred to as the standard statistical model: value of y is a linear function of x plus random noise.
y is called the dependent or response variable and x is called the independent or predictor variable.
Method of Least Squares
Find the slope, β1, and intercept, β0 that minimize
S(β0,β1)=∑i=1n(yi−β0−β1xi)2
∂β0∂S=−2∑i=1n(yi−β0−β1xi)=0
∂β1∂S=−2∑i=1nxi(yi−β0−β1xi)=0
Method of Least Squares
β^0=yˉ−β^1xˉ
β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
The least sequares estimates are unbiased:
E(β^j)=βj, for j=0,1.
Variance of Parameter Estimates
From the standard statistical model, Var(yi)=σ2 and Cov(yi,yj)=0 when i=j
Var(β^0)=n∑i=1nxi2−(∑i=1nxi)2σ2∑i=1nxi2
Var(β^1)=∑i=1n(xi−xˉ)2σ2
Relationship to Hypothesis Testing
Define the residual sum of squares (RSS) to be
RSS=∑i=1n(yi−β^0−β^1xi)2
An unbiased estimate of σ2 is given by s2=n−2RSS where n−2 is used instead of n because two parameters have been estimated from the data, yielding n−2 degrees of freedom.
Relationship to Hypothesis Testing
If the errors, ei, are independent normal random variables, then βi^ for i=0,1 are normally distributed and it can be shown that
sβ^iβ^i−βi∼tn−2
where tn−2 is a t distribution with n−2 degrees of freedom. We would use this to test the null hypothesis H0:β1=0, for example.
Relationship to Correlation
Let's define the following quantities:
sxx=n1∑i=1n(xi−xˉ)2
syy=n1∑i=1n(yi−yˉ)2
sxy=n1∑i=1n(xi−xˉ)(yi−yˉ)
The correlation coefficient between x's and y's is r=sxxsyysxy and β^1=sxxsxy; therefore r=β^1syysxx.
Relationship to Correlation
Let's standardize the variables: ui=sxxxi−xˉ and
vi=syyyi−yˉ. This yields suu=svv=1 and suv=r. The least squares line for predicting v from u has:
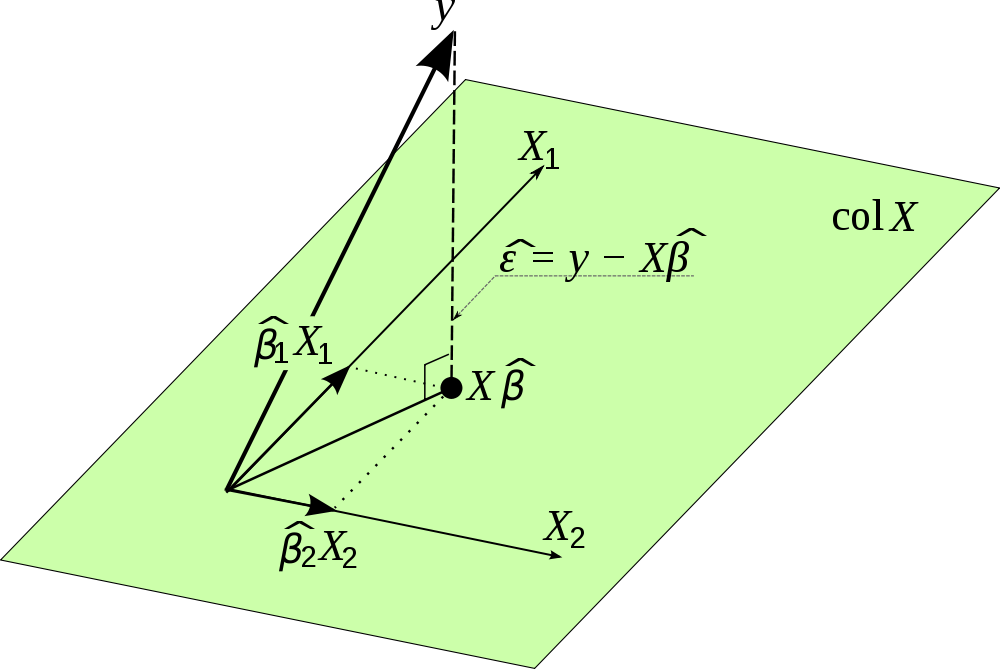
P (Projection Matrix) projects onto the p-dimensional subspace of Rn spanned by the columns of X.
Y^ is a projection of Y onto the p-dimensional subspace spanned by the columns of X.
Multiple Linear Regression
Multicolinearity
If there is perfect multicolineararity among the columns of the X matrix (i.e., they are linearly dependent), then X has less than full rank, XTX cannot be inverted and a unique solution for β does not exist. Even if there is not perfect multicolinearity but highly correlated input variables, then interpreting the fitting coefficients and their significance can become problematic.
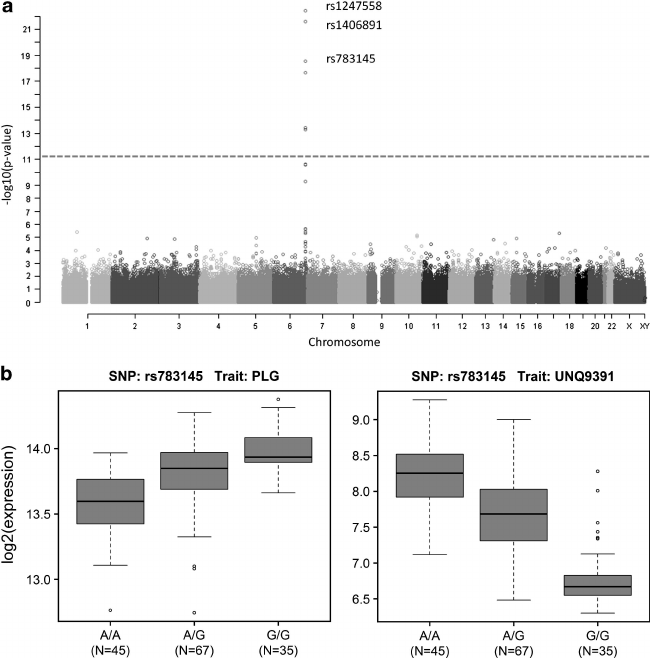
Contingency Tables
Phenotype/Genotype
SNP
No SNP
Total
Disease
n11
n12
n1.
No Disease
n21
n22
n2.
Total
n.1
n.2
n
Contigency Tables
Table containing I rows and J columns with numbers for each category from n total samples. Assume the probability of being in cell i,j is πij.
Define πi.=∑j=1Jπij and π.j=∑i=1Iπij as the mariginal probabilities that an observation with fall in the ith row and jth column, respectively.
If the row and column classifications are independent of each other, then πij=πi.π.j.
Contigency Tables
Consider testing the the following null hypothesis: H0:πij=πi.π.ji=1,…,I and j=1,…,J versus the alternative that the πij are free.
Under H0, the maximum likelihood estiamte of πij is
π^ij=π^i.π^.j=nni.nn.j
Under the alternative, the maximum likelihood estiamte of πij is π~ij=nnij.
Chi-Squared Test of Independence
We will perform the Pearson's chi-squared test which is asymptotically equivalent to the likelihood ratio test. Define Pearson's chi-squared statistic:
χ2=∑i=1I∑j=1JEij(Oij−Eij)2
where Oij=nij are the observed counts and Eij=nπ^ij=nni.n.j are the expected counts under the null hypothesis.
Chi-Squared Test of Independence
Pearson's chi-squared statistic is then given by
χ2=∑i=1I∑j=1Jni.n.j/n(nij−ni.n.j/n)2
which is χ2 distributed with k degrees of freedom.
The degrees of freedom are the number of independent counts minus the number of independent parameters estimated from the data.
Chi-Squared Test of Independence
There are IJ−1 independent counts since n is fixed. Also, (I−1)+(J−1) indepedent parameters were estiamted from the data. Thus,
k=IJ−1−(I−1)−(J−1).
We would calculate p-values by using the chi-squared statistic and integrating a chi-squared distribution with k=(I−1)(J−1) degrees of freedom.